Bayesian Wi‑Fi
TLDR: Bayes rule is cool. Stable Wi‑Fi rules. The former can give us the latter.
Transmitting Wi‑Fi frames over noisy radio spectrum is far from trivial. You see, every second or so the Wi‑Fi driver in your router needs to make thousands of nitty-gritty little decisions: Which modulation rate should the Wi‑Fi chipset use for this particular data frame? Should several frames be aggregated together and sent in a single radio burst? Should the transmission be protected with a RTS-CTS handshake? How many times should the Wi‑Fi chipset retry the transmission if no acknowledgement frame is received back? And if all the transmission attempts fail, then what? Should we try again with different parameters, or simply drop the frame?
Most of the time the Wi‑Fi driver in your router makes sensible decisions, and you enjoy stable and fast Wi‑Fi. But, as we’ve all experienced, there are times when your Wi‑Fi turns less than stellar. In my experience this is often because the Wi‑Fi driver in your router has become “overwhelmed” by a challenging radio environment, one in which the usual “rules of thumb” no longer work very well.
So what can we do to improve the stability and performance of Wi‑Fi? How about replacing the “rules of thumb” with the one rule that rules them all: Bayes rule. This is the first post in a series that will explore this opportunity to advance the frontiers of knowledge and push the human race forward. :P With a bit of luck we will some day arrive at an implementation of a Bayesian Wi‑Fi rate control algorithm for the Linux kernel, so that anyone can run it on a low-cost consumer Wi‑Fi router (by replacing its firmware with OpenWrt).
The Problem and the Usual Rules of Thumb
The Linux kernel defines an
interface for rate control algorithms in net/mac80211.h.
So in very practical terms the problem is to implement the operations needed to fill in a struct
rate_control_ops. The main challenges are get_rate which, as the name implies, is called
for each frame before it is transferred to the Wi‑Fi chipset for transmission over the air, and
tx_status which is called after transmission to report back the result. The former should pick
the modulation rates and other radio parameters to use for transmission, and pack them into an array of
ieee80211_tx_rates,
each with its own
mac80211_rate_control_flags.
The latter should evaluate the result of the transmission and learn from it; so that a better
selection can be made the next time get_rate is called.
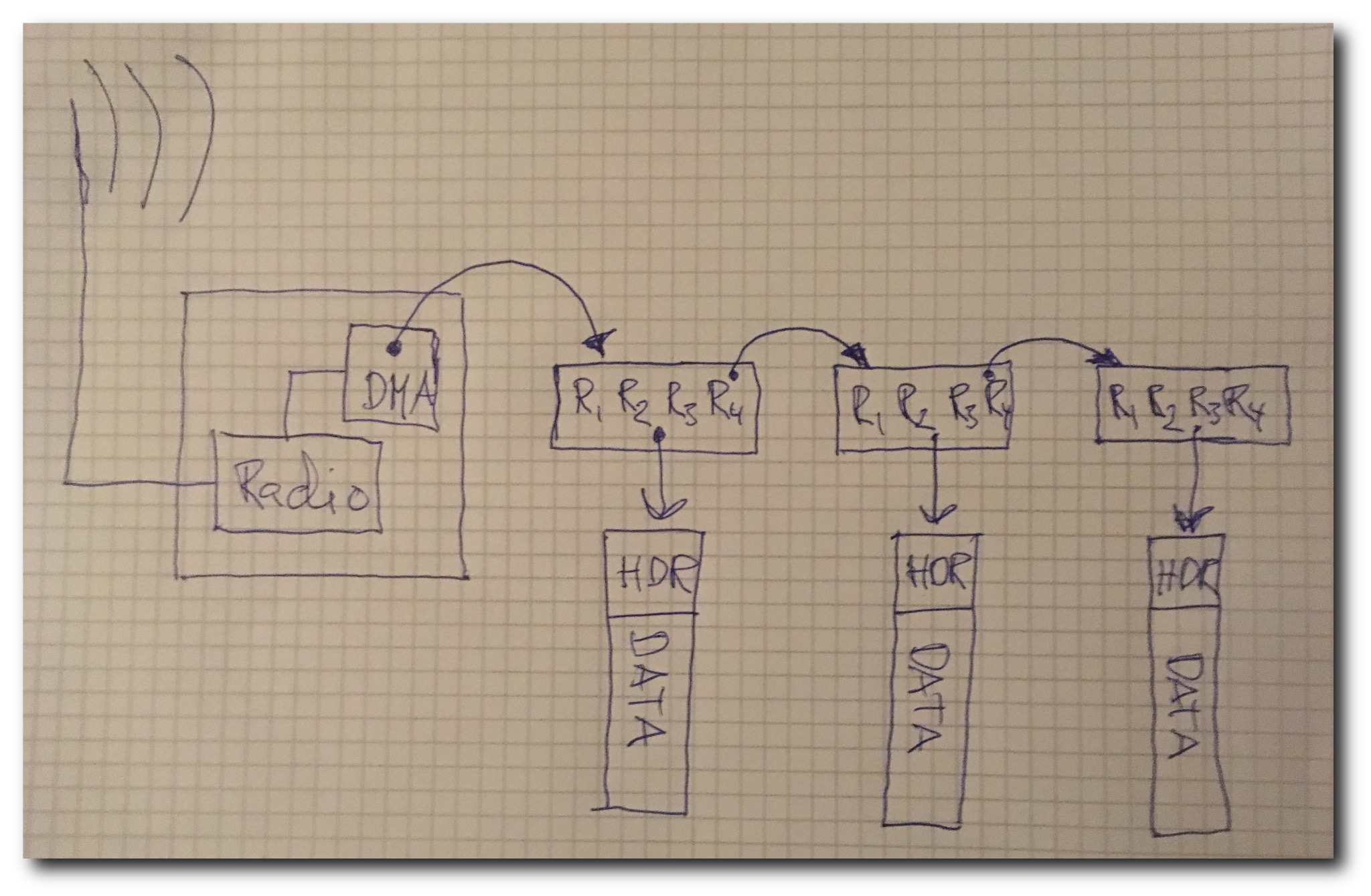
Sketch of a Wi‑Fi chipset DMA chain: So-called DMA descriptors, each containing the memory address of the frame data and radio parameters (R1 to R4), are chained together before being transferred to the Wi‑Fi chipset and transmitted over the air. Arrows represent "pointers".
The default rate control algorithm in Linux is called
Minstrel.
Most of its implementation is in
the file net/mac80211/rc80211_minstrel_ht.c.
It’s widely cited in the literature and
often used as a benchmark when evaluating novel algorithms. In most radio environments it performs
reasonably well, but it’s based on very hand-wavy statistical reasoning. Essentially it just keeps
an exponentially weighted moving average (EWMA) of the packet error rate (PER) for each combination
of radio parameters supported by the communicating Wi‑Fi chipsets. It then constructs retry
chains of radio parameters (corresponding to R1 through R4 in the sketch above)
based on very simple “rules of thumb”:
-
first try the radio parameters with the highest expected throughput, then
-
try the radio parameters with the second highest expected throughput, then
-
try the radio parameters with the highest expected success probability, and finally
-
try using the lowest modulation rate supported by both the communicating Wi‑Fi chipsets.
From time to time Minstrel will try some unexpected radio parameters in an attempt to learn. It’s this behavior that has given it its name: like a wandering minstrel the algorithm will wander around the different rates and sing wherever it can.
There are a number of problems with these “rules of thumb” and I suspect that they lead to suboptimal performance in more challenging radio environments. I could go on and on about them, but I think it suffices to say that Minstrel is not based on very sound statistical reasoning.
The State of the Art
So what would a rate control algorithm based on sound statistical inference look like? Fortunately I’m not the first person to ask that question; there’s a large body of research papers on the subject out there.
To me the most promising theoretical approach seems to be a Bayesian one where we cast the rate adaptation problem in the shape of a multi-armed bandit problem: different radio parameters are like different slot machines in a casino, each with an unknown (but potentially very different) reward distribution, and the task of the rate control algorithm is similar to that of a gambler in trying to determining which slot machine to play in order to maximize reward in some sense. There’s an excellent paper by Richard Combes, Alexandre Proutiere, Donggyu Yun, Jungseul Ok and Yung Yi titled “Optimal Rate Sampling in 802.11 Systems” that takes this approach.

Each choice of radio parameters can be modeled as a slot machine with an uncertain reward distribution, transforming the rate adaptation problem into a (restless / contextual) multi-armed bandit problem. Slide from David Silvers lecture on the trade-off between exploration and exploitation in muli-armed bandit problems.
So we have a research paper and we need an implementation. How is that research? Not so fast, Combes et al makes one unfortunate simplifying assumption:
If a transmission is successful at a high rate, it has to be successful at a lower rate, and similarly, if a low-rate transmission fails, then a transmitting at a higher rate would also fail.
This may sound like a safe assumption but it is simply not true in the complex world of MIMO, collisions and interference. Just one example is that higher rates often have a higher success probability than lower rates when errors are primarily caused by collisions or interference (as is common in busy radio environments), simply because a packet sent at a higher rate stays in the air for a shorter period of time and is therefore less likely to be “shot down” by sporadic interference.
So what can we do? Is there a way to salvage Combes et als results? Probably, but I’m not sure I’m the person to do it. On the other hand I feel rather sure that we could do something in the same general direction. For example Pedro A. Ortega has done some interesting work on Thompson sampling and Bayesian control that I think could be applied to Wi-Fi rate adaptation. There’s also a large body of research on so-called contextual bandit problems and restless bandit problems that could be applicable.
First Steps
I can see a couple of ways forward. One is very theoretical and includes reading up more on the contextual bandit problem.
Another is more practical and includes modeling the rate adaptation problem as a Dynamic Bayesian Network and applying Thompson sampling. A first prototype using existing code for approximate inference in DBNs (like libDAI or Mocapy++) and a network simulator like NS-3 could probably be put together relatively quickly. This could be an interesting Master’s thesis project, for example.
Yet another approach is even more practical and can be described as “writing a better Minstrel”, directly targeting the Linux kernel. The focus would be on simplifying assumptions like working with conjugate priors. This would be of less scientific interest, but perhaps more useful in the short term.
Which approach to take depends on who wants to join in the fun. :) We need everything from theoreticians to testers, so please don’t be shy!
Want to Join In?
Want to join in the fun, and get your name on a research paper and/or some pretty cool open source code? Shoot me an email at bjorn@openias.org or fill in the form below!